
今回は以下の本の紹介をいたします。

- 加嵜 長門 田宮 直人 丸山 弘詩
- マイナビ出版 2017-03-27
「ビッグデータ分析・活用のための」と描かれている通り、文中は大規模データを想定したSQL文が並びます。このビッグデータな時代、色んなSQL本が出版されていますが、ここまで実用的で、かつサンプル例が揃った本に初めて出会いました。
著者はDMM.comラボに勤められているエンジニアの方だそうですが、この書籍の元ネタは現場で実際に使っているSQL文か著者の個人的なメモなのではないでしょうか。それくらい「痒い所に手が届く」「困った時に知っておきたい」サンプル例ばかりです。
今回は、この本で着目すべき3つの注目点を簡単に纏めてみました。
その1:非エンジニア向けの易しい解説書スタンス
そもそもビッグデータと一口に申しても、データを管理しているエンジニア、データを分析するデータサイエンティスト、データからインサイトを得たいマーケターや営業や経営者、立場によって「データ」は違って見えるはずです。
エンジニアにとっては「記録」。データサイエンティストにとっては読み解いた先に何かあるかもしれない「数字」。そしてマーケターや営業や経営者にとっては「宝の地図」か「隠したい不都合な真実」。
少し極端に表現していますが、同じ「データ」なのに役割が違うだけでここまで違う顔を持っていいのかという疑問もあります。
大企業であれば役割が分かれることのメリットがデメリットを上回る場合もあるでしょうが、中小企業・ベンチャーだと役割を分けようにも人手不足で分けられないのが現状ではないでしょうか。
しかし、役割が分断しているのは理由があって、お互いが使っている「言語」が分からないという(個人的には結構切実な)問題が隠されています。
エンジニアはSQL書けるし、データサイエンティストはSPSSやSASやRやPythonで統計解析ができるし、マーケターは消費者心理が分かるし、営業はモノを売れます。
しかし、どうにも役割間には「見えない壁」のようなものがあって、fluentdでS3に格納しているアクセスログをRedshiftなりBigQueryなりに食わせて集計・集約するとなるとデータサイエンティストは「それ、僕できるかな…」と不安げな表情を浮かべます。
データサイエンティストが欲しいデータを、エンジニアが必ずしも一発で用意してくれるとは限らないんですけどね。

その壁を壊そう!というのがこの本の趣旨だと私は解釈しました。文中にも、上記に近しいイメージ図が紹介されています。
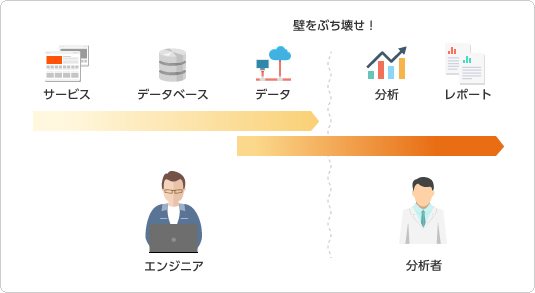
ちなみに、私は開発部出身でして、SQLを書くのが結構好きです。というかデータを格納するテーブル設計の思想を読み解くのが好きなのです。鄙びた温泉旅館に置かれた積み木パズルを解くような楽しさがあります。
過去に、ER図すら無い2TBあるデータベースを渡されて「分析して何か発見してください」というマゾの極地に立った経験があるのですが、その時も少しずつ全体像が浮かんで行く感覚にワクワクしたのを覚えています。
データサイエンティスト協会もこの「壁」については認識されておられて、公開されているスキルチェックリストにはデータサイエンス力以外にデータエンジニアリング力、ビジネス力なども含まれています。
私が思うに、SQL書ければもっと仕事捗るだろうに!と思う役割はマーケターさんです。
というか、個人的には「SQL書けないマーケターもうgood night」ではないでしょうか。
消費者心理を読めるマーケターさんが自分で勝手にデータの抽出までやれたら最強です。全てがマーケターさんで完結するからです。
デジタルマーケティングの世界ではあそこまでエクセルに塗れているのに、RDBに向き合ってSQL書けない理由が全く理解できません。最近は営業でも強制的にTreasureDataでクエリを書かせる企業もあるそうですけど。
元USJの森岡さんが「数字マーケティング」という造語を生んでまで市場啓蒙されていますが、あまり反応も無いようです。
計量マーケティングとでも言えばいいのに。英語にするとMarketingMetrics…あっ。
その2:超実践的な事例の数々
英語の文法本は文法を教えるのが役目ですから、例文は糞の役にも立ちません。一方で、ビジネス英会話は英語に慣れるのが役目ですから、文法は学べません。
この本は、その間の良いとこ取りをしたような本です。
Chapter3〜Chapter7でSQLの作法がみっちり学べるし、しかもビジネスの実践で使えるSQLばかりが登場するので、登場する幾つかはそのままコピペして使えると思います。
各章の見出し名が「やりたいこと軸」になっているので、逆引きもし易い構成になっています。
しかもデータを取り出すシステムの対象として「PostgreSQL」「Hive」「Redshift」「BigQuery」「SparkSQL」を前提にSQL文が用意されており、「コピペしたらエラーが出たから使えない!」という事態を防いでくれるでしょう。
私自身、PostgreSQLの関数群をよく使います。
しかし、たまに「あれ、なんだっけ?」となります。自分のやりたい内容をSQLに置き換えようにも関数が浮かばないのです。
たぶん紙に手書きでテーブルを書いて「このデータをこう集約してこう並べたい!」と言えば、誰かが分かってくれると思うのですが、そういうときに限ってみんな忙しそうなんですよね。
Googleは、自分の知っている単語があれば答えを出してくれるのですが、そもそもの答えが分からない場合は検索しようにも検索できません。
そういうときにこの本1冊あれば、「あー、そうそう!lagだ!lagでOVERだ!」と思い出せるようになるのではないでしょうか。
というか、すでに私はそういう機会に何度か巡り会いました。
この本には「あれなんだっけ」がだいたい載っていますね。
その3:地味に嬉しい「分析術」
Chapter8では、分析術が紹介されています。
地味に嬉しいのは、アソシエーション分析やレコメンドスコアの付け方をSQLベースで紹介されている事例がいくつかあって「Rじゃなくてもできるんだぜ!」感が伝わってきて嬉しいです。
実際にはRで{arules}とやりゃ一発だし、著書もそれは理解されているんでしょうが、この時代にファミコン出てきた感あるじゃないですか。
あー、このレコメンドスコアで俺は三上悠亜さんレコメンドされてるのか、なんて考えたりするのです。
データサイエンティストと呼ばれる人の中には、RやPythonを使って関数を使って実行することに慣れてしまって、どういう計算をしているか知らぬまま使っている場合もあるようですし、それに対するアンチテーゼ感を受け取りました。
最後に
エンジニアが読むより、データサイエンティストやマーケターこそ読むべき本だと思うのです。
- 加嵜 長門 田宮 直人 丸山 弘詩
- マイナビ出版 2017-03-27
本当ならこの書評のタイトルは「SQL書けないマーケターもうgood night」にしたかったぐらいです。だから、アイキャッチもSuchmos風。
それくらい、今の時代はマーケターこそSQL書けたら便利なんだぜ!という熱い思いを最後に本コンテンツを締めたいと思います。ありがとうございました。