
株式会社ロックオンには「企業理念の理解浸透、体現促進」を目的として理念プロジェクトなる体制があります(参考記事はコチラ)。
理念プロジェクトでは現在、「OKAGE SUN プロジェクト」を推進しています。
登録フォームを設けてロックオンで働く人全員(正社員、バイト、子会社とか一切関係なく!)の「おかげさんです(ありがとう!)」という声を集め、WEB上で掲載しているのです。
WEB上では、仕事上での「ありがとう」という掛け声が飛び交います。例えば以下のように。


「ありがとう」って言えば「ありがとう」って言う。
こだまでしょうか?いいえ、誰でも。
そんな職場って、素敵やん。
今回は、そんな素敵さの「見える化」に挑戦します。
データの分布:「ありがとう」の内訳
フォームのデータは、プロジェクトが始まった2014年10月分から、およそ2,500件分あります。営業日が260日だとして、およそ1日あたり5件の投稿がある計算になります。
こうした取り組みは年月が経つことに徐々に過疎るものですが、今でもコンスタントに投稿され続けているので、今やロックオンに根付いた文化だと言えるでしょう。
データフォーマットは以下のように、「あなたのお名前」「相手のお名前」「理由」の3項目で構成されています。
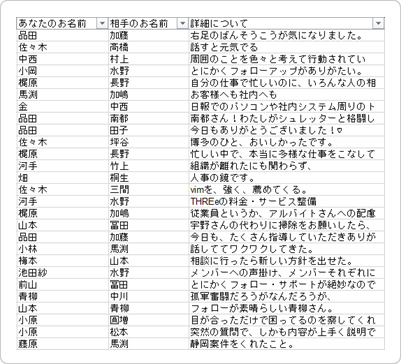
まず、「あなたのお名前」(以降、投稿者)の分布から見てみましょう。
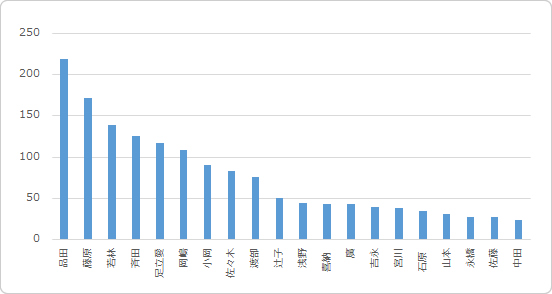
圧倒的に投稿回数が多いのが品田、次に藤原の両名。品田は理念プロジェクトのメンバーとしても現在活躍中の新卒2年目です。
投稿数の多い上位者は殆どが東京支社勤務か新卒・若手組で占められていて、こういうのってノリとか勢いとか大事だよな〜と感じます。
λ=1の指数分布に見えなくもないのですが、それは脇に置いて話を進めます。
次に、「相手のお名前」(以降、おかげな人)の分布を見てみましょう。
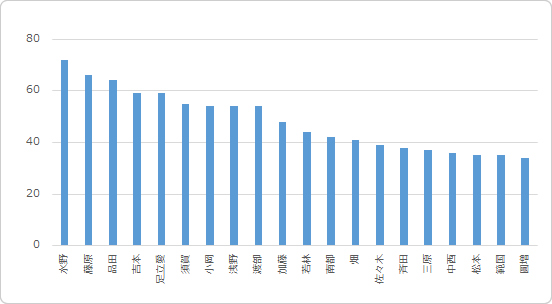
投稿者の分布とは違った傾向になりました。
上位10名全て東京支社勤務が占めました。仲の良さ、人間関係の濃さが伺い知れます。
ただ、「おかげな人」=「ありがとうと感謝されている人」だから、下位の人はダメなのか?と言うと、決してそんなことは無いでしょう。
普段滅多に投稿しない人の「ありがとう」って、凄く重みがあると思うからです。そんな貴重な「ありがとう」を言われた人、素敵じゃないですか?
つまり量も大事だけど質も大事。両方含めて、ありがとうの「見える化」したいのです。どうすればいいでしょうか?
系列パターンマイニングで「ありがとう」は見える化できる
系列パターンマイニング(Sequential Pattern Mining)を使って、質と量を含めた「ありがとう」の見える化に挑みます。
今回もRを使って分析します。
この系列パターンマイニングのpackage名が“arulesSequences”である通り、”arules”すなわちアソシエーション分析に似ています。
その違いに少しだけ触れておきましょう。
アソシエーション分析とは、POS分析でおなじみの手法です。
POS分析と言えば「ビール」と「おむつ」の話が登場しますが、そこで使われている手法がアソシエーション分析です。
超ざっくり分けると、以下のようになります。

一緒に何が買われやすいか、その後に何が買われやすいか、イメージのデータを用意しました。

1回の買い物で見れば、4回中3回はビールとおむつが一緒に買われていることがわかります。これがアソシエーション分析で明らかになります。
Aさん、Bさんの買い物で見れば、2人ともビールを買った後に大福が買われていることがわかります。これが系列パターンマイニングで明らかになります。
データ量が少なければ目視でも分かりますが、レコードが何千、何万とあると、順番という制約を気にしながらパターンを見つけるのは相当骨が折れる作業ですよね。
この手法を使えば、「投稿者」の投稿のうち、誰に「ありがとう」と声をかけていて、その「ありがとう」はどれくらい貴重かが明らかになりそうです。
「ありがとう」がこだまする
まず最初に、分析用にデータを以下のように加工しておきます。
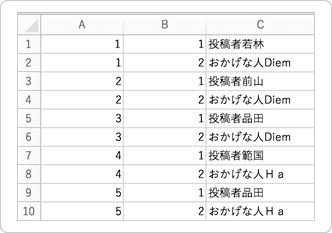
A列に組み合わせ、B列に順番、C列に「投稿者」「おかげな人」それぞれの名前があります。
それでは、arulesSequencesを使って分析を始めましょう。
install.packages("arulesSequences")
library(arulesSequences)
os <- read_baskets(“./okaseq.csv", info = c("sequenceID","eventID"))
os.sp <- cspade(os, parameter=list(support = 0), control=list(verbose=TRUE))
rules <- ruleInduction(os.sp, confidence=0, control=list(verbose=TRUE))
rule.df <- rule.df[rule.df["lift"] >= 1.0,]
rule.df <- head(rule.df[order(-rule.df$confidence),], n=10)
rule.df
rule support confidence lift
107 <{投稿者大塚}> => <{おかげな人品田}> 0.0004868549 1.0000000 32.09375
199 <{投稿者三宅}> => <{おかげな人徳島}> 0.0004868549 1.0000000 128.37500
203 <{投稿者川村}> => <{おかげな人徳島}> 0.0004868549 1.0000000 128.37500
230 <{投稿者小嶋}> => <{おかげな人藤原}> 0.0004868549 1.0000000 31.12121
252 <{投稿者久世}> => <{おかげな人渡部}> 0.0004868549 1.0000000 38.03704
592 <{投稿者岸本}> => <{おかげな人小林}> 0.0004868549 1.0000000 102.70000
621 <{投稿者村上}> => <{おかげな人小川}> 0.0004868549 1.0000000 158.00000
949 <{投稿者山野}> => <{おかげな人岡嶋}> 0.0004868549 1.0000000 64.18750
721 <{投稿者山岸}> => <{おかげな人三原}> 0.0009737098 0.6666667 37.00901
5 <{投稿者赤川}> => <{おかげな人檜本}> 0.0004868549 0.5000000 146.71429
ここで、説明を省いた支持度(support)、確信度(confidence)、リフト(lift)の説明をしておきます。
支持度(support)とは、ruleの組み合わせがsequenceID全件に占める比率を指します。つまり、支持度が高いということは、この組み合わせの登場の多さを意味します。
例えば「大塚 => 品田」という投稿は全体で0.0487%を占めるということです。
確信度(confidence)とは、eventIDの中に投稿者Xがあるときに次以降におかげな人Yが含まれる比率を指します。つまり、確信度が高いということは、投稿者にとってその投稿が占める割合が高いことを意味します。
例えば、「赤川 => 檜本」という投稿は、赤川さんにとって50%を占めるということです。
リフト(lift)とは、確信度÷おかげな人が全体で占める比率を指します。この値が1以上だとルールとしては有効だと言われています。
このリフトが一番解りにくいのですが、あまり告白しない人が色んな人から告白される人にした告白って貴重だよね、と捉えれば良いかもしれません。
このコンテンツでは、支持度は量、確信度は質とだけ理解いただければ良いかと思います。
さて、まずは支持度が高い順の結果を見てみましょう。TOP30を描いてみます。
「見せる化」が重要なので、DiagrammeRというパッケージを使います。
install.packages("DiagrammeR")
library("DiagrammeR")
rule.df$LHS <- str_replace_all(rule.df$rule,"=>.+","")
rule.df$RHS <- str_replace_all(rule.df$rule,".+=>","")
rule.df$LHS <- rule.df$LHS %>% str_replace_all("\\{投稿者","") %>% str_replace_all("\\}","")
rule.df$LHS <- rule.df$LHS %>% str_replace_all("\\<","") %>% str_replace_all("\\>","")
rule.df$RHS <- rule.df$RHS %>% str_replace_all("\\{おかげな人","") %>% str_replace_all("\\}","")
rule.df$RHS <- rule.df$RHS %>% str_replace_all("\\<","") %>% str_replace_all("\\>","")
rule.df$mermaid <- paste0(rule.df$LHS, "-->|", (floor(rule.df$confidence*1000)/10), "%|", rule.df$RHS)
rule.df$mermaid
mermaid(paste("graph TD",Reduce(function(...){paste(...,sep="\n")},rule.df$mermaid),sep="\n"))
正規表現下手くそですいません、と思いつつ、その結果は以下の通りです。
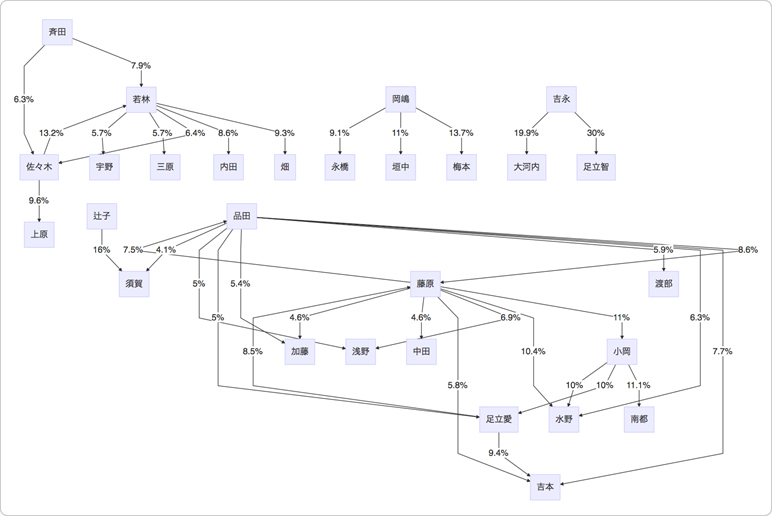
矢印上の数字は確信度を表しています。
見事に東阪で分かれました。まぁ、めったに絡みがありませんからね…。
面白いのは、「ありがとう」のこだまが起きていることです。
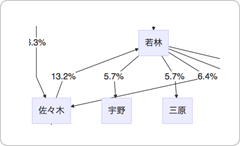
佐々木から若林に「ありがとう」の13.2%が、若林から佐々木に「ありがとう」の6.4%がこだましています。支持度高いながら、ありがとうの山彦が発生するほど、2人の関係性は強いということでしょうか。
実際、2名は同じ部署に所属し、同じPJメンバーとして仕事をした期間も長く、まさに相棒のような存在なのです。
他にも登場回数が圧倒的に多い藤原・品田間でもこだまが発生していて、仲良いよな〜と改めて思います。知らんけど。
次に、確信度が高い順の結果を見てみましょう。こちらが普段滅多に投稿しない人の「ありがとう」ってやつです。同じくTOP30を描いてみます。
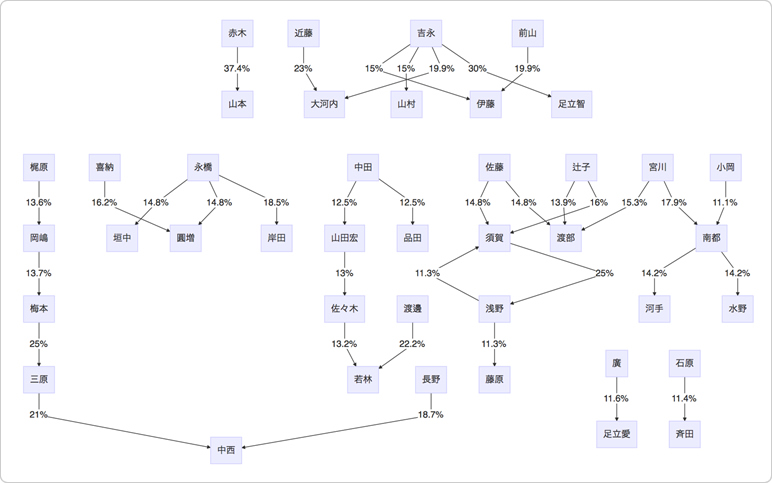
ガラッと傾向が変わりましたね。
量から質に変えても、同じようにこだまは起きていて、須賀から浅野に「ありがとう」の25%が、浅野から須賀に「ありがとう」の11.3%がこだましています。
先ほどと同じく、2人とも同じ部署で辛酸辛苦を味わった仲間だからこそですね。知らんけど。
ところで質に転換して見てみると、部署を跨いだ「ありがとう」も出てきました。
例えば、梅本(ソリューション事業部)→三原(開発部)や近藤(コーポレートコミュニケーション部)→大河内(EC-CUBE事業部)などです。
部署の垣根を越えて、ありがとうと言える。それって、素敵やん。
こうした「ありがとう」のやり取りを可視化することで、この2人で何か仕事のやり取りがあったんだなとか、通常は見えない人間関係が浮かんでくるので、人事・労務管理的にも良い面はあるのかもしれませんね。
系列パターンマイニングで「態度変容」もわかるのではないか?
最後に、マーケティングへの応用事例も考えておきます。
系列パターンマイニングなら順番を考慮してXのあとにYが起こりやすいことが分かるなら、Yを直接CVのあった広告媒体と定義して、何の広告あればYが起こりやすいか、すなわち「態度変容」に繋がりやすい間接効果広告媒体を見つけられるのではないでしょうか。
CVしているユーザーの広告接触履歴も、CVしていないユーザーの広告接触履歴も綯い交ぜて系列パターンマイニングにかけてしまえばいいのです。
唯一、考慮しなければならないのは、系列パターンマイニングは順序は考慮できても、時間の感覚は考慮できないことにあります。
すなわちリスティング広告をクリックして3ヶ月にメルマガ経由でCVに至るのと、リスティング広告をクリックして1日後にメルマガ経由でCVに至るのでは、リスティング広告そのものを態度変容を与えたものかどうかの考え方が変わります。
一応このあたりの解となる論文は発表されていて、以下を読む限り一定時間感覚以上で囲むか区切るのが良さそうです。
アイテム間の距離を考慮した Sequential Pattern Mining の提案
https://dspace.wul.waseda.ac.jp/dspace/bitstream/2065/697/1/1g01p043.pdf
興味のある方、良かったら一緒に研究してみませんか?お問い合わせはこちら。
以上、お手数ですがよろしくお願いします。