
みなさんこんにちは。前回のパインアメの分析に引き続き今回もマメ研に寄稿させていただくことになりました。
今回はテキストマイニングを使って歌詞の表現は年代によって異なるのかを分析してみたいと思います。
歌詞は時代を映す鏡
僕的には歌詞とはその時代を映し出す鏡のようなものだと思っています。
うまくは説明できないのですが、昔の曲を聴くとなんだか昔の曲だなぁなんて感じたり、最近の曲を聴くと「今はこういう曲が流行りだよね!」なんて感じたりします。
(ちなみに僕の生まれは1994年ですが、僕の感覚で「昔の曲」は90年代くらいの曲になります。この記事を読んでくださっている方からしたら若いなぁて思われるのでしょうか…)
昔と比較するとかなり歌詞の内容が変わってきているのではないでしょうか。
さらにメロディーが加わるとものすごい変化がありそうです。
そこで、実際どのように歌詞が変化してきているのか、各年代でどんな特徴があるのかをテキストマイニングで分析してみたいと思います。
クラスタリングで年代を分類
まずはクラスタリングで、各年代を分類してみます。
年代によって歌詞が異なっていて、歌詞の表現が日々変化しているのであれば、各年が隣り合わせになるようなイメージが浮かびます。
近い年代の曲同士は歌詞の表現が似ているのではないでしょうか。2005年~2007年のクラスタ、2010年~2012年のクラスタなどなど。
実際にやってみましょう。
今回扱うデータは、僕の生まれた年である1994年〜2016年を対象に各年のシングル売上ランキング上位10曲です。
各年代ごとに歌詞のデータをマージして、「1994.txt」「1995.txt」…としました。
Rでは「RMeCab」パッケージを用いて、テキストファイルを形態素に分解します。なんだかマメ研ではKH CoderやMeCabがお馴染みになってきたような気がします。
#パッケージの読み込み library(RMeCab) #データの読み込み data <- docMatrix(“merge”, pos = c(“動詞”,”形容詞”,”名詞”)) #不要なレコードの削除 data <- data[row.names(data) != “[[LESS-THAN-1]]”,] data <- data[row.names(data) != “[[TOTAL-TOKENS]]”,] #行列の入れ替え data <- t(data) #クラスタ分析 data.d <- dist(data, “canberra”) data.h <- hclust(data.d, “ward.D2”) plot(data.h)
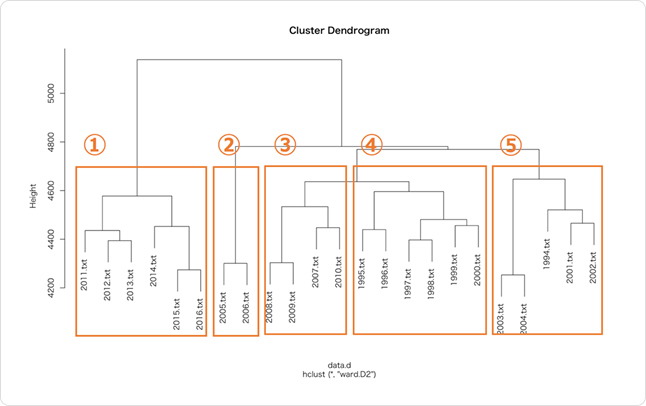
ここでは①〜⑤のようなクラスタに分けてみました。
プロットの結果を見てみると、思ったより綺麗に分類されました!
クラスタ①は2011~2016とここ最近に分類されています。
クラスタ④に関してはほぼほぼ90年代を表していますね。
他のクラスタもほとんどが連続する年が隣り合わせになっていることがわかります。
また、僕の生まれた年である1994年と2011年・2012年が似ているようです。これもある意味特徴といえるでしょう。
各クラスタのサマリ
各年代・クラスタではどのような表現や単語があるのか詳細を見てみましょう。
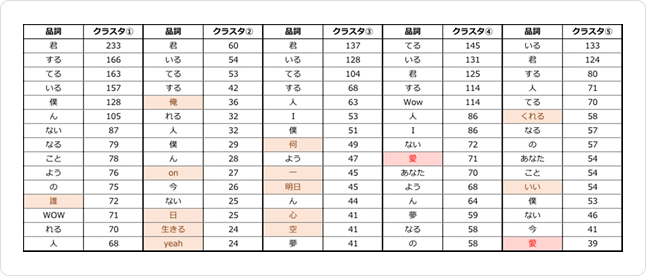
どのクラスタに対しても重複していない単語には色付けをしています。
これを見てみると、ほとんどの歌詞には「君」という単語が多く出てくるようですね。独り言の歌詞というよりは、自分と相手がいるというストーリーを描いた歌詞が大半のようです。
「君」は2人称ですが1人称の表現はクラスタ④以外だと「僕」が上位に入っています。
また、クラスタ④(約90年代)では「僕」という単語ではなく「I」という単語で一人称を表しているようです。この年代では1人称を英語で表現している歌詞が多いという特徴がありそうですね。
他にもどの年代でも多く出現しそうな「愛」という単語が上位に入っています。このクラスタではラブソングなどが特に人気だったのでしょうか。
クラスタ⑤でもトップ15に「愛」という単語がランクインしているので、この年代でもラブソングが人気そうですね。
各年代の恋愛偏差値
先ほどどの年代でも「愛」という単語は上位に入っていそうだと言いました。
僕の予想では「愛」や「love」という単語は、なんかはどの年代でも上位にランクインしそうな気がしたのですが、クラスタ④や⑤以外では上位にそのような単語はありませんでした。
そこでちょっと面白そうだったので、「愛」ワードにフォーカスして、各クラスタの「恋愛偏差値」というものを算出してみようと思います!
どのクラスタや年代が愛情多き歌詞があるのか偏差値をもとに探ってみましょう。
今見ているのは上位15までの単語なので、実際はもっと「愛」や「love」「好き」などを含む単語や表現が異なるが同じ意味を持つ単語あると思います。
例えば、「好き」という単語と「スキ」という単語は同じ意味を持ちますが、形態素解析においては別々の単語として扱われてしまいます。また、英単語ですと大文字と小文字も区別されてしまいます。
なので、各クラスタの単語全てから「愛」「love」「好き」などの愛情を意味する単語が含まれているものを抽出し、合計値を出します。
それをここでは愛情得点とでもしておきましょう。その合計値をもとに偏差値を求めてみます。
結果は以下のようになりました。
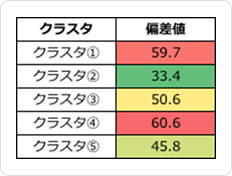
クラスタ①は、先ほどの上位15までの単語には愛情系のワードは含まれていませんでしたが、愛情偏差値がとても高くなっています。
実際にどのようなワードで愛情を表現しているのかを確認してみ他ところ、「愛す」や「愛しい」などのワードが多く含まれていました。
先ほど上位15に「愛」のワードがあったクラスタ④と⑤ですが、④に関しては①同様に他の愛情系ワードが多く含まれていていました。僅差で④の方が偏差値は高くなっています。
⑤に関しては、上位に「愛」というワードが入っているものの、その他の愛系ワードがなかったので偏差値は低くなっています。
ちなみにクラスタごとではなく、各年代別に見てみると以下のようになりました。
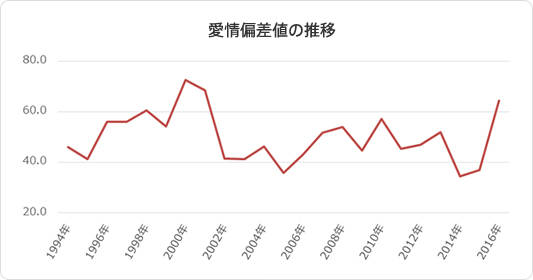
2000年と2001年の愛情偏差値がかなり高めになっていることがわかります。その年以降は一気に偏差値は減少していますが、2016年にまた高くなっています。
今年は約15年ぶりにラブソングの人気が期待される年になるのかもしれませんね!
最後に、この偏差値ですが「恋している人の数」や「カップルの数」かなんかに相関がありそうと考えていたのですが、そんなデータはどこにもなく調べるのもほぼ無理…。
そこで統計データを探っていたところ「婚約数」というデータがありましたので、そのデータを使って相関係数を求めてみたところ0.47とそこまで高くはないですが、まぁまぁ相関があったりしました。
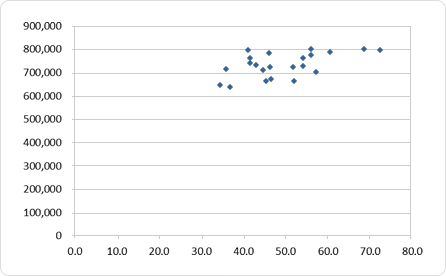
カップルが増るから恋愛に関する歌が増えるのか、恋愛に関する歌が増えたからカップルが増えたのか、それとも第3の要因があって疑似相関しているだけなのか…?
まとめ
今回は歌詞をテキストマイニングして最終的に愛情系ワードにフォーカスしてみました。
他のワードでも偏差値を出してみてこの年代はこういうワードの偏差値が高いという見方をするのも面白そうです。
また、今回は平成生まれの歌詞を分析しましたが、昭和の歌詞も含めて平成と昭和の比較をしたり、時系列での変化を見てみるのも面白そうだと思いました。
以上です。