
2010年4月から始まったマメ研は10月で6.5周年を迎えます。色々あった6.5年間。
そんな感謝の気持ちをALWAYS風のアイキャッチに込めてみました。
さて、当研究所のサイトは、月2~3本の更新頻度ながらコツコツとマーケティングとデータに関するあらゆる研究成果を発表してきました。
おかげで、少しずつ認知度も向上し、サイトのアクセス数もようやく少しずつ増えてきました。
我武者羅にやってきたので、本当に「いつの間にか増えた」といった感じですが、今回は「それはいつの日だったのか」を定義する分析手法をご紹介します。
改めて振り返るマメ研の6年半
改めてマメ研発足から今日までの6年半を振り返ってみましょう。週次毎のSU数を面グラフで表現してみました。初代、2代目、3代目の時代の色分けも合わせてマッピングしてみます。
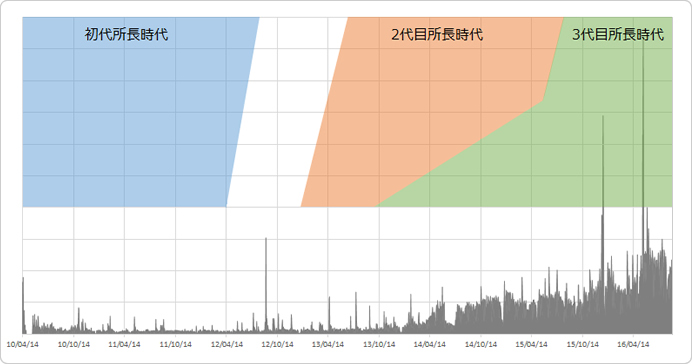
ここ直近でもっとも伸びているのは「おじさん分析」で、その手前が「有馬記念分析」ですね。
横軸のSU数はあえて表示していませんが、両コンテンツのFBいいね数から、おおよその単位を弾き出して下さい。
こうしてみると、2014年4月ごろから面グラフの範囲が広がっているように見えます。
そこでRのstl関数を使って6年半(334週)分の週次SU数をトレンド(trend)、周期変動(seasonal)、残差(remainder)の3つに分けて見てみます。
ts.su<-ts(mm$su,frequency=52, start=c(2010, 15)) stl.su <- stl(ts.su,s.window="per") plot(stl.su)
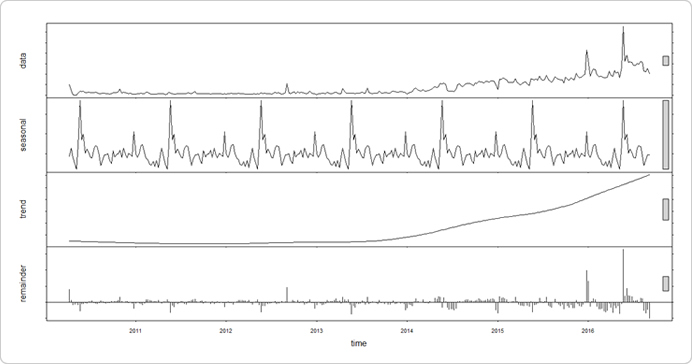
トレンドで見ると2013年後半からSU数が伸び始め、いったん滑らかになるものの、2015年半ば以降は右肩上がりの急成長を続けています。3代目所長、鼻高々。
ただ、こうした「変化点」を長期トレンドでのみ判断するのは危険ですし(季節変動どうするの?残差は考慮しなくていいの?等)、何よりもう少し細かい粒度で見たいですよね。
理想は昨日と違う今日はいつ始まったのかを知ることです。それを「構造変化点を知る」と言い換えましょう。これは逐次確率比検定を用いれば見えてきます。
逐次確率比検定とは?
逐次確率比検定とは「仮説検定」の応用的手法にあたります。
そもそも「仮説検定」とは、帰無仮説と対立仮説を立て、①帰無仮説を棄却しないか、②帰無仮説を棄却し対立仮説を支持するか、何れかを観測値に基づいて決める統計手法です。
帰無仮説と対立仮説の考え方は「性能テストの結果にダメ出しをしてください」というコンテンツに記載しているのでご覧下さい。
通常の仮説検定は標本の数が決まっており、その標本に基づいて検証が行われます。
ですが逐次確率比検定は最初に少量の標本を与え、上記の①か②のみでなく、新たに③そのいずれとも言えない場合は結論を留保しさらにデータを収集する、という第3の選択肢が登場させた統計手法です。
品質管理工学や医学診断などでは比較的にメジャーに使われているようです。
計算式は意外とシンプルです。標本の中から無作為に抽出したデータZiを1つずつ観測し、以下の式で尤度比(確率比)λiを求めます。

分母のPは帰無仮説H0の下でデータZiを観測する確率、分子のPは対立仮説H1の下でデータZiを観測する確率を表します。
λiが求まると、それが境界値より上か、下かを確認します。
②λiがC2[(1-β/α)]超過:帰無仮説H0棄却する
③λiがC1以上C2以下:結論を留保する
※αは第1種過誤(帰無仮説が正しいのに誤って仮説を棄却する誤り)、βは第2種過誤(帰無仮説が誤っているのに仮説を採択してしまう誤り)を指します
逐次確率比検定は通常の仮説検定より標本が少なく済む等の文献(逐次検定の学習評価への適用について)がありますが、今回の本筋では無いので脇に置いておいて進めていきます。
この検定方法について詳しく知りたい人は以下のググった結果を参考にしてみて下さい。
Google検索結果:逐次確率比検定
標本を時系列データである6年半(334週)分の週次SU数として、この逐次確率比検定を用いて、どのタイミングで構造変化が起きたか見てみましょう。
逐次確率比検定で時系列データの「構造変化」を明らかにする
検定を行う前に、まず時系列データから予測式を作成し予測直線を求めます。さらに各時点データと予測式の誤差の標本分散を計算して誤差の許容区間を設定します。
先ほどの長期トレンド等から考えて、データのちょうど折り返し地点である167週までで予測式を作成します。168週目以降のどのタイミングで「構造変化」が起きたか確認することにします。
dat<-read.csv("mameken_week.csv")
dat_base<-dat[1:167,]
lm_out<-lm(su~X,data=dat_base)
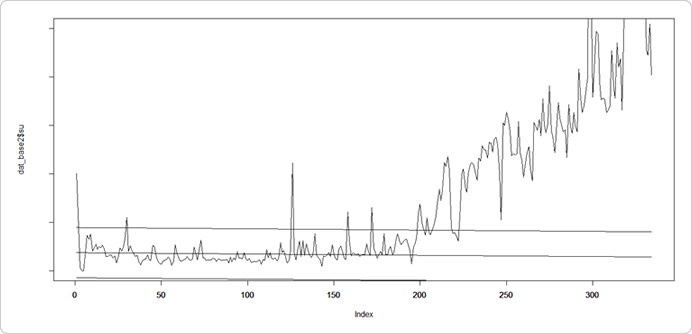
次に仮説を設定します。帰無仮説は「構造変化は起きていない」、許容範囲(±2σ)を超える確率θ0は10%以下とします。対立仮説は「構造変化は起きている」、許容範囲(±2σ)を超える確率θ1は90%以上とします。
また第1種過誤、第2種過誤をそれぞれ設定し、C1 とC2をそれぞれ求めます。今回はそれぞれ0.01としておきます。
合わせてλ0を1としておきます。
では168週目以降のSU数を逐次確認していきます。168週目がi=1とし、週毎のSU数を確認して、検定にかけていきます。
最初に、SU数と予測式の誤差を確認します。許容範囲内(±2σ内)であれば尤度比(確率比)λ1=1としてi=2のデータを確認していきます。以降、許容範囲外(±2σを超える)まで確認が続きます。
もし許容範囲外であれば、以下の計算式を用いて尤度比(確率比)λ1を更新します。更新した値を先述したとおりの検定を実施し、あとは帰無仮説が棄却されるまで続けます。
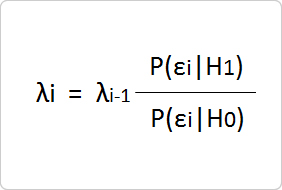
今回のSU数だと201週(2014年02月09日週)目で帰無仮説は棄却され「構造変化は起きている」と判断できることがわかりました。
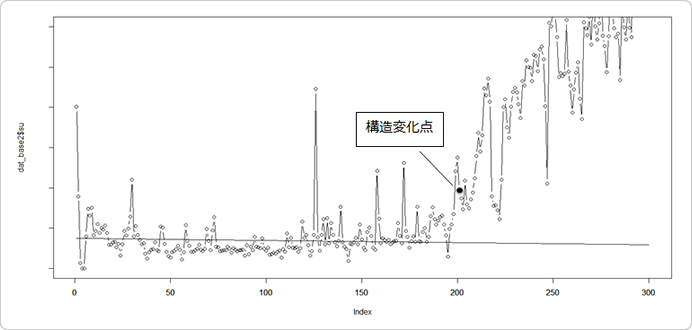
θ1を20%にすると、202週(2014年02月16日週)目で帰無仮説が棄却されたので、2014年2月前半~中盤には昨日と違う今日が始まったと言える事がわかりました。
この頃何をしていたかと言うと、記事を更新し続けるだけではダメで、サイト全体のSEO対策に年明けから取り組み始めました。タイトルを変更したり、キーワードプランナーと睨めっこして言い回しを変えたり、2ヵ月ほど悪戦苦闘したことを覚えています。
あれは無駄では無かったんだなぁ…と思うと胸が熱くなります。ちなみにこのタイミングではアクセス数微増かぁ~ぐらいにしか捉えておらず、結局質の良いコンテンツを出し続けるしかないよね、という結論に落ち着きました。
構造変化を見落としていたわけですね。
ちなみに、予測式の区間を100週目までとし、101週目以降で構造変化点を探す検定を行いましたが、上記グラフでピョコンと飛び跳ねている126週目、158週目、172週目を「変化点」として帰無仮説は棄却されませんでした。
1時点だけでは構造変化と見ないようにもなっていて、局地的な変化に反応せず、データそのものの変化に反応する良い検定手法だと思っています。
運用型広告の出稿停止の判断にも使えないか?
1地点の変化ではなく構造自体の変化に反応するのであれば、例えばリスティングやDSPなどの運用型広告での出稿停止可否の判断に使えるのではないでしょうか。
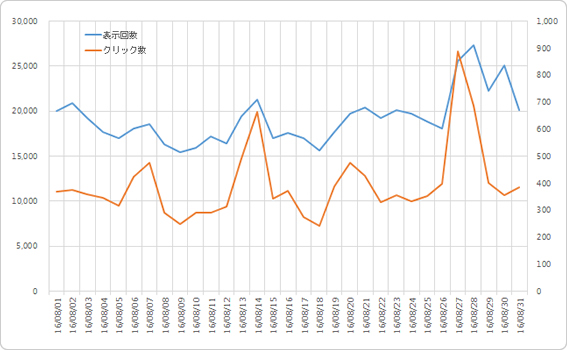
例えば上記の広告運用結果(このデータは社内で実際に運用しているデータを一部加工しています)。
X軸を表示回数(単位は万)、Y軸をクリック数として、i日目の累積数をplotします。
このデータ、実は11日目以降のクリック数に×0.8して意図的に減らしています。最初折れ線グラフを見たとき、解らなかったかと思います。点線が元のCTR、実践が加工後のCTRです。
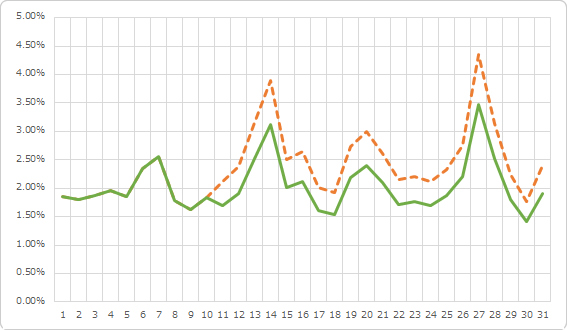
このデータで逐次確率比検定を行い、構造変化が検出できるかどうか確かめてみましょう。
最初の7日間で予測式を作成し、8日目以降で構造変化が起きていないか検定を行います。
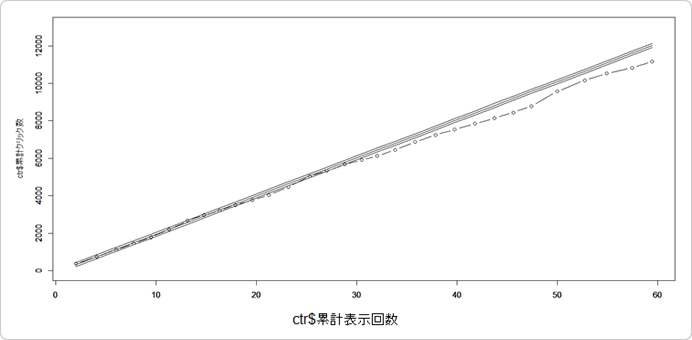
θ0は5%、θ1は95%で検定を行った結果、12日目で構造変化を検出しました。構造変化点は11日ですから2日目で気付くことができたわけで、なかなか優秀ですね。
上のグラフだと、さすがに20日目あたりには違和感を抱きそうですが、今回の手法を用いればそれより1週間近く前に機械的に気付けるわけです。
今回の方法を突き詰めて考えればX軸に累積CV数・Y軸に広告コストとしてCPAの構造変化点を見るでもいいでしょうし、今回のデータは日単位ですが時単位で見てもいいかもしれません。
θ0は厳しめに設定しておいて、変化点を検出しやすいようにしておけば、それが結果的に誤検知であっても広告主にとっては無駄に広告コストをかけずに済む可能性が高まるわけで「ある程度運用してみたけどこのクリエイティブ×キーワードで出稿するのは辞めた」と判断する材料になるのでは?と考えております。
初速から悪い場合はどうやって検知するんだよ!というツッコミを貰いそうですが、それは予測式として今までの運用結果を用いれば済むのではないかと考えております。
ちなみにマーケターの皆さんは、どうやって出稿停止の是非を判断されておられるのでしょうか。
そのあたりの貴重なご意見頂ければ、今回の手法を強化させることに繋がるので本コンテンツのご意見・ご感想なんかも合わせてメッセージいただけると幸いです。(※もちろん共同研究のお誘いでも!)
まとめ
何事もやり続けることが大事ですね。
今回紹介した逐次確率比検定は、用いた運用型広告のSTOP/GOの判断にも使えそうで、人間の勘や感覚値だけでなく第3の観点としてアドバイス機能としての価値が出せそうです。
もう少しマメ研で深堀りしたいと思います。目指せ、マーケティングロボット!
以上、お手数ですがよろしくお願いいたします。
参考文献
(続)時系列と構造変化点の検出:http://www.bk-web.jp/2015/0102/bkseminar.php